 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry
Jan 30, 2026Large language models (LLMs) are widely used as reference-free evaluators via prompting, but this "LLM-as-a-Judge" paradigm is costly, opaque, and sensitive to prompt design. In this work, we investigate whether smaller models can serve as efficient evaluators by leveraging internal representations instead of surface generation. We uncover a consistent empirical pattern: small LMs, despite with weak generative ability, encode rich evaluative signals in their hidden states. This motivates us to propose the Semantic Capacity Asymmetry Hypothesis: evaluation requires significantly less semantic capacity than generation and can be grounded in intermediate representations, suggesting that evaluation does not necessarily need to rely on large-scale generative models but can instead leverage latent features from smaller ones. Our findings motivate a paradigm shift from LLM-as-a-Judge to Representation-as-a-Judge, a decoding-free evaluation strategy that probes internal model structure rather than relying on prompted output. We instantiate this paradigm through INSPECTOR, a probing-based framework that predicts aspect-level evaluation scores from small model representations. Experiments on reasoning benchmarks (GSM8K, MATH, GPQA) show that INSPECTOR substantially outperforms prompting-based small LMs and closely approximates full LLM judges, while offering a more efficient, reliable, and interpretable alternative for scalable evaluation.
HyperEdit: Unlocking Instruction-based Text Editing in LLMs via Hypernetworks
Dec 14, 2025Instruction-based text editing is increasingly critical for real-world applications such as code editors (e.g., Cursor), but Large Language Models (LLMs) continue to struggle with this task. Unlike free-form generation, editing requires faithfully implementing user instructions while preserving unchanged content, as even minor unintended modifications can break functionality. Existing approaches treat editing as generic text generation, leading to two key failures: they struggle to faithfully align edits with diverse user intents, and they often over-edit unchanged regions. We propose HyperEdit to address both issues. First, we introduce hypernetwork-based dynamic adaptation that generates request-specific parameters, enabling the model to tailor its editing strategy to each instruction. Second, we develop difference-aware regularization that focuses supervision on modified spans, preventing over-editing while ensuring precise, minimal changes. HyperEdit achieves a 9%--30% relative improvement in BLEU on modified regions over state-of-the-art baselines, despite utilizing only 3B parameters.
Gaussian Splatting-based Low-Rank Tensor Representation for Multi-Dimensional Image Recovery
Nov 19, 2025



Tensor singular value decomposition (t-SVD) is a promising tool for multi-dimensional image representation, which decomposes a multi-dimensional image into a latent tensor and an accompanying transform matrix. However, two critical limitations of t-SVD methods persist: (1) the approximation of the latent tensor (e.g., tensor factorizations) is coarse and fails to accurately capture spatial local high-frequency information; (2) The transform matrix is composed of fixed basis atoms (e.g., complex exponential atoms in DFT and cosine atoms in DCT) and cannot precisely capture local high-frequency information along the mode-3 fibers. To address these two limitations, we propose a Gaussian Splatting-based Low-rank tensor Representation (GSLR) framework, which compactly and continuously represents multi-dimensional images. Specifically, we leverage tailored 2D Gaussian splatting and 1D Gaussian splatting to generate the latent tensor and transform matrix, respectively. The 2D and 1D Gaussian splatting are indispensable and complementary under this representation framework, which enjoys a powerful representation capability, especially for local high-frequency information. To evaluate the representation ability of the proposed GSLR, we develop an unsupervised GSLR-based multi-dimensional image recovery model. Extensive experiments on multi-dimensional image recovery demonstrate that GSLR consistently outperforms state-of-the-art methods, particularly in capturing local high-frequency information.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025
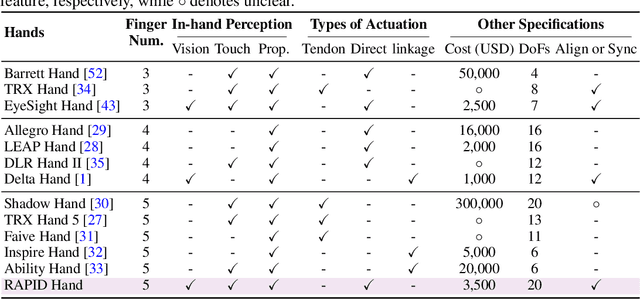


This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
NaviDiffusor: Cost-Guided Diffusion Model for Visual Navigation
Apr 14, 2025Visual navigation, a fundamental challenge in mobile robotics, demands versatile policies to handle diverse environments. Classical methods leverage geometric solutions to minimize specific costs, offering adaptability to new scenarios but are prone to system errors due to their multi-modular design and reliance on hand-crafted rules. Learning-based methods, while achieving high planning success rates, face difficulties in generalizing to unseen environments beyond the training data and often require extensive training. To address these limitations, we propose a hybrid approach that combines the strengths of learning-based methods and classical approaches for RGB-only visual navigation. Our method first trains a conditional diffusion model on diverse path-RGB observation pairs. During inference, it integrates the gradients of differentiable scene-specific and task-level costs, guiding the diffusion model to generate valid paths that meet the constraints. This approach alleviates the need for retraining, offering a plug-and-play solution. Extensive experiments in both indoor and outdoor settings, across simulated and real-world scenarios, demonstrate zero-shot transfer capability of our approach, achieving higher success rates and fewer collisions compared to baseline methods. Code will be released at https://github.com/SYSU-RoboticsLab/NaviD.
Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
Apr 14, 2025Recent advancements in diffusion-based imitation learning, which show impressive performance in modeling multimodal distributions and training stability, have led to substantial progress in various robot learning tasks. In visual navigation, previous diffusion-based policies typically generate action sequences by initiating from denoising Gaussian noise. However, the target action distribution often diverges significantly from Gaussian noise, leading to redundant denoising steps and increased learning complexity. Additionally, the sparsity of effective action distributions makes it challenging for the policy to generate accurate actions without guidance. To address these issues, we propose a novel, unified visual navigation framework leveraging the denoising diffusion bridge models named NaviBridger. This approach enables action generation by initiating from any informative prior actions, enhancing guidance and efficiency in the denoising process. We explore how diffusion bridges can enhance imitation learning in visual navigation tasks and further examine three source policies for generating prior actions. Extensive experiments in both simulated and real-world indoor and outdoor scenarios demonstrate that NaviBridger accelerates policy inference and outperforms the baselines in generating target action sequences. Code is available at https://github.com/hren20/NaiviBridger.
OPG-Policy: Occluded Push-Grasp Policy Learning with Amodal Segmentation
Mar 06, 2025Goal-oriented grasping in dense clutter, a fundamental challenge in robotics, demands an adaptive policy to handle occluded target objects and diverse configurations. Previous methods typically learn policies based on partially observable segments of the occluded target to generate motions. However, these policies often struggle to generate optimal motions due to uncertainties regarding the invisible portions of different occluded target objects across various scenes, resulting in low motion efficiency. To this end, we propose OPG-Policy, a novel framework that leverages amodal segmentation to predict occluded portions of the target and develop an adaptive push-grasp policy for cluttered scenarios where the target object is partially observed. Specifically, our approach trains a dedicated amodal segmentation module for diverse target objects to generate amodal masks. These masks and scene observations are mapped to the future rewards of grasp and push motion primitives via deep Q-learning to learn the motion critic. Afterward, the push and grasp motion candidates predicted by the critic, along with the relevant domain knowledge, are fed into the coordinator to generate the optimal motion implemented by the robot. Extensive experiments conducted in both simulated and real-world environments demonstrate the effectiveness of our approach in generating motion sequences for retrieving occluded targets, outperforming other baseline methods in success rate and motion efficiency.
Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications
Feb 19, 2025Large Language Models (LLMs) have transformed natural language processing, yet they still struggle with direct text editing tasks that demand precise, context-aware modifications. While models like ChatGPT excel in text generation and analysis, their editing abilities often fall short, addressing only superficial issues rather than deeper structural or logical inconsistencies. In this work, we introduce a dual approach to enhance LLMs editing performance. First, we present InstrEditBench, a high-quality benchmark dataset comprising over 20,000 structured editing tasks spanning Wiki articles, LaTeX documents, code, and database Domain-specific Languages (DSL). InstrEditBench is generated using an innovative automated workflow that accurately identifies and evaluates targeted edits, ensuring that modifications adhere strictly to specified instructions without altering unrelated content. Second, we propose FineEdit, a specialized model trained on this curated benchmark. Experimental results demonstrate that FineEdit achieves significant improvements around {10\%} compared with Gemini on direct editing tasks, convincingly validating its effectiveness.
Infant Agent: A Tool-Integrated, Logic-Driven Agent with Cost-Effective API Usage
Nov 02, 2024



Despite the impressive capabilities of large language models (LLMs), they currently exhibit two primary limitations, \textbf{\uppercase\expandafter{\romannumeral 1}}: They struggle to \textbf{autonomously solve the real world engineering problem}. \textbf{\uppercase\expandafter{\romannumeral 2}}: They remain \textbf{challenged in reasoning through complex logic problems}. To address these challenges, we developed the \textsc{Infant Agent}, integrating task-aware functions, operators, a hierarchical management system, and a memory retrieval mechanism. Together, these components enable large language models to sustain extended reasoning processes and handle complex, multi-step tasks efficiently, all while significantly reducing API costs. Using the \textsc{Infant Agent}, GPT-4o's accuracy on the SWE-bench-lite dataset rises from $\mathbf{0.33\%}$ to $\mathbf{30\%}$, and in the AIME-2024 mathematics competition, it increases GPT-4o's accuracy from $\mathbf{13.3\%}$ to $\mathbf{37\%}$.
Dynamic 3D Point Cloud Sequences as 2D Videos
Mar 02, 2024Dynamic 3D point cloud sequences serve as one of the most common and practical representation modalities of dynamic real-world environments. However, their unstructured nature in both spatial and temporal domains poses significant challenges to effective and efficient processing. Existing deep point cloud sequence modeling approaches imitate the mature 2D video learning mechanisms by developing complex spatio-temporal point neighbor grouping and feature aggregation schemes, often resulting in methods lacking effectiveness, efficiency, and expressive power. In this paper, we propose a novel generic representation called \textit{Structured Point Cloud Videos} (SPCVs). Intuitively, by leveraging the fact that 3D geometric shapes are essentially 2D manifolds, SPCV re-organizes a point cloud sequence as a 2D video with spatial smoothness and temporal consistency, where the pixel values correspond to the 3D coordinates of points. The structured nature of our SPCV representation allows for the seamless adaptation of well-established 2D image/video techniques, enabling efficient and effective processing and analysis of 3D point cloud sequences. To achieve such re-organization, we design a self-supervised learning pipeline that is geometrically regularized and driven by self-reconstructive and deformation field learning objectives. Additionally, we construct SPCV-based frameworks for both low-level and high-level 3D point cloud sequence processing and analysis tasks, including action recognition, temporal interpolation, and compression. Extensive experiments demonstrate the versatility and superiority of the proposed SPCV, which has the potential to offer new possibilities for deep learning on unstructured 3D point cloud sequences. Code will be released at https://github.com/ZENGYIMING-EAMON/SPCV.